Cleaning Big Data
eft Columnist Steve Brady gives an insight on the tools available to aggregate data from multiple sources; as well as to clean the data up
In my last article I wrote about Big Data and how there are tools already on your desk that can handle large amounts of data. Excel’s Powerpivot can really slice up the data, making it simple to digest. Unfortunately, “big data” problems are often more complicated, and working through all the different data sources, and errors in the data can give the most sturdy analysts indigestion. (Okay, enough with this analogy.)
There are many tools available now to aggregate data from multiple sources, and clean up the data as well. For instance, one might want to take an existing customer dataset, marry it with demographic data from a government census, and draw comparison between your customers and the population. Perhaps you even want to tie these two data sources into other market and economic data to tease out further information that can shape new product development or marketing strategies.
A recent article in the New York Times highlights the challenges with collecting and cleaning data. In the scenario above, it is possible that the data collected from different sources uses different definitions for the same data, or groups the data in different sets. For instance, if you collect data based on age-groups what ages do you aggregate? 18-24, 25-34, 35-44, etc? Or do you collect the data in 18-24, and then 25-44, and then 45-65? Or what about simply having differences in how data is coded? Is monthly sales data reported in thousands of dollars (so $250.3 is $250,300) or millions? ($.253?) Does that match reporting on the demographics so that you can easily compare your revenue (and per customer spend) to average income for the age group? As the article points out, cleaning up these data problems (being a “data janitor” as they call it) is the very thing that keeps analysts up at night.
Several companies are making it their business to help you clean up, and understand, yours by developing tools that can work through the data, clean it, and report it.
One such tool is from a company called “Clear Story.” They have as their mission to “dramatically simplify accessing, exploring, and analyzing data.” They have developed their tools to do just that. They collect data from multiple sources, internal and external to your company, and provide the tools to not only provide analysis but to convey the information in chart and graph form. being able to see the connections, and start to understand and tell a story about the data is key to what they provide.
Another company positioned to assist in making sense of your data is Competitive Insights. In an interview I conducted with their CEO Richard Sharp in 2012, he explained that they “take the data as it exists in each of those operating environments. We bring it together. We cleanse it. Then we provide it back to them in different functional views, so that they can, in fact, make better decisions to reduce costs and increase the profitability of the operation.”
But--and this is a big one--what if you can’t afford to play with these tools? Is there an (free) option?
Of course there is! And it may not come as much of a surprise that it has it’s origins in Google. Google acquired an application originally called “ Freebase Gridworks” then renamed Google Refine, and now named Open Refine. This tool is designed specifically to explore big data, providing the mechanism to clean the data, transform data by merging it with other data sets, and ultimately output that data into other data analysis tools.

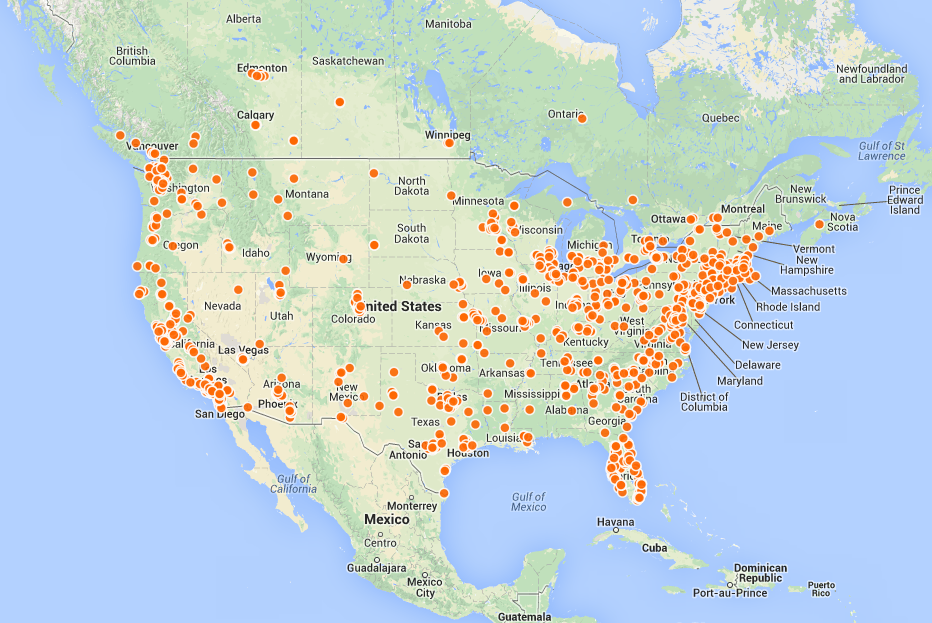
I was able to import data from a small company, clean up the datasets (there were “fat fingered” errors in the address records, for instance, transform that data by linking the data to Google Maps, and then using a tool from CartoDB (a “Freemium” service) create a map showing that company’s customer base across North America. (See below).
Open Refine is a javascript program that runs in your (Chrome) browser, but it runs local to your machine. (You can download the latest release, and developers releases here.) All the data crunching and analysis is done locally on your machine (of course, if your data is coming from an external source that data will remain at the source, but it will pull it what it needs to do the analysis locally). It is available for Windows, Mac, and Linux operating systems.
One other useful feature of Open Refine is that it is an Open Source project. As such, others are free to write to it, improve it, and even create extensions for others to use. Some of the extensions (such as Crowdsourcing extension) have very specific use-cases while others truly extend the capabilities of the tool (just as the pivot and scatterplot extension). The extensions currently available are:
-
Crowdsourcing extension - by Zemanta
-
DBpedia extension - by Zemanta
-
History tools, pivot tool and scatterplot tool using D3 - by VIB-BITS
-
Diff plugin- by VIB-BITS
-
LMF Extension (to be migrated to Apache Marmotta after summer) - by Salzburg Research
-
Named-Entity Recognition - by Ruben Verborgh (Free Your Metadata)
-
RDF extension - by DERI
The following video explains Google Refine/Open Refine in a quick 7 minute introduction.
View a video about Open Refine here
Big Data can lead to big insights, and potentially big profits, if one is able to clean it, aggregate it, and make sense of it. Take a few minutes and learn about the tools mentioned here. What do you think you can do with the knowledge this data can bring to you?
Share your thoughts and your discoveries with us here.
Related Content

